Unlocking the Power of Machine Learning: A Comprehensive Guide to Amazon SageMaker


AWS partner dedicated to startups
- 2000+ Clients
- 5+ Years of Experience
- $10M+ saved on AWS
As the world becomes increasingly data-driven, organizations rely more on machine learning to gain a competitive edge. One of the leading platforms in this domain is Amazon SageMaker.
Amazon SageMaker provides a complete set of tools to build, train, and deploy machine learning models at scale. In this guide, we’ll provide you with step-by-step instructions and real-world examples on how to preprocess data, select appropriate algorithms, and evaluate model performance.
Table of Contents
Understanding the Basics of Machine Learning
Machine learning is a branch of artificial intelligence that enables computers to learn from data and make predictions or take actions without being explicitly programmed. It is the driving force behind many modern technologies, from recommendation systems to self-driving cars.
To understand machine learning, it is important to grasp the basic concepts. At its core, machine learning involves training a model on a dataset to make predictions or decisions. The model learns patterns and relationships within the data and uses that knowledge to make accurate predictions on new, unseen data.
There are different types of machine learning algorithms, including supervised learning, unsupervised learning, and reinforcement learning. Supervised learning involves training a model on labelled data, where the input and output pairs are known. Unsupervised learning, on the other hand, deals with unlabeled data and aims to find patterns or clusters within the data. Reinforcement learning involves training a model to make decisions based on rewards or punishments.
Understanding these fundamental concepts will provide a solid foundation for working with Amazon SageMaker and harnessing its full potential.
What is Amazon SageMaker and Why Use It?
Amazon SageMaker is a fully managed machine learning service provided by Amazon Web Services (AWS). It is designed to simplify the process of building, training, and deploying machine learning models at scale. With SageMaker, you can quickly and easily build, train, and deploy models without having to worry about the underlying infrastructure.
There are several reasons why you should consider using Amazon SageMaker for your machine-learning projects:
- SageMaker provides a seamless and integrated environment for the entire machine-learning workflow. From data preprocessing and model training to deployment and monitoring, all the necessary tools and services are available within the SageMaker platform.
- Another key advantage of SageMaker is its scalability. With SageMaker, you can easily train models on large datasets and deploy them to handle high-volume predictions. The platform automatically scales the underlying infrastructure to handle the workload, allowing you to focus on building and improving your models.
- SageMaker also offers a wide range of built-in algorithms and frameworks, making it easier to get started with machine learning. Whether you are working on image classification, natural language processing, or time series forecasting, SageMaker provides pre-built algorithms that can be easily customized to suit your specific needs.
By using Amazon SageMaker, you can significantly reduce the time and effort required to build and deploy machine learning models. This allows you to focus on the core aspects of your business, such as analyzing data and making informed decisions.
Key Features and Benefits of Amazon SageMaker
Amazon SageMaker offers a comprehensive set of features and benefits that make it a powerful platform for machine learning. Here are some of the key features and benefits of SageMaker:
Fully Managed
SageMaker takes care of all the underlying infrastructure, including provisioning, scaling, and maintenance. This allows you to focus on building and training models without the need for manual setup or management.
Integrated Environment
SageMaker provides a unified environment for the entire machine-learning workflow, from data preprocessing to model deployment. This integration streamlines the development process and improves productivity.
Built-in Algorithms
SageMaker offers a wide range of built-in algorithms and frameworks, including popular ones like XGBoost, TensorFlow, and PyTorch. These pre-built algorithms can be easily customized and fine-tuned to meet your specific requirements.
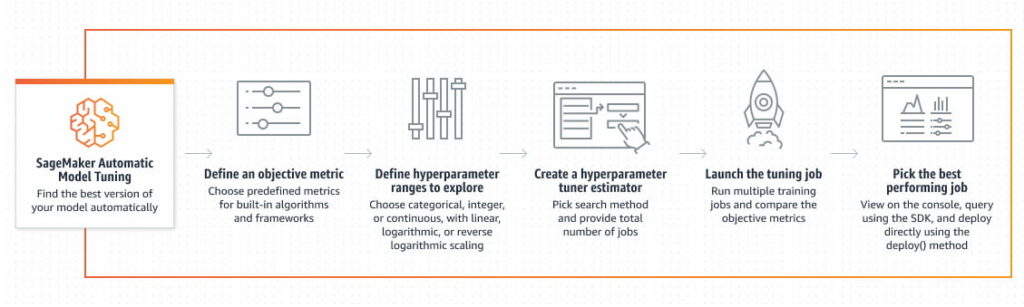
Hyperparameter Tuning
SageMaker includes a feature called Automatic Model Tuning, which automates the process of tuning hyperparameters. Hyperparameter tuning is crucial for optimizing model performance, and SageMaker simplifies this process by automatically searching through the hyperparameter space for the best set of values.
Scalability
SageMaker can handle large datasets and high-volume predictions with ease. The platform automatically scales the underlying infrastructure to handle the workload, ensuring that your models perform efficiently even under heavy usage.
Model Deployment
SageMaker allows you to easily deploy trained models to production with a few clicks. The platform supports both real-time and batch predictions, making it suitable for a wide range of applications.
By leveraging these features and benefits, you can accelerate your machine-learning projects and achieve better results in less time.
Getting Started with Amazon SageMaker
Now that you have a good understanding of the basics of machine learning and the key features of Amazon SageMaker, it’s time to get started with the platform. This section will guide you through the process of setting up your SageMaker environment and preparing your data for machine learning.
Step 1: Setting up your SageMaker environment
To start using Amazon SageMaker, you will need an AWS account. If you don’t have one already, you can sign up for a free account on the AWS website. Once you have an AWS account, you can access SageMaker through the AWS Management Console.
To set up your SageMaker environment, follow these steps:
- Log in to the AWS Management Console.
- Navigate to the SageMaker service.
- Click on “Create notebook instance”.
- Provide a name for your notebook instance and choose an instance type.
- (Optional) Choose a VPC and security group for your notebook instance.
- Click on “Create notebook instance” to create your instance.
Once your notebook instance is created, you can launch Jupyter notebooks and start working on your machine-learning projects.
Step 2: Preparing your data for machine learning
Before training a machine learning model, it’s essential to prepare the dataset. This process includes cleaning, addressing missing values, and transforming the information into a format suitable for training. Proper preparation ensures that the model can learn effectively from the dataset.
Here are some common steps involved in preparing data for machine learning:
Data Cleaning
Remove any duplicate or irrelevant data. Handle missing values by either deleting the rows or imputing the missing values with appropriate methods.
Feature Engineering
Extract meaningful features from the raw data. This may involve transformations, scaling, encoding categorical variables, or creating new features based on existing ones.
Data Splitting
Split your dataset into training and validation sets. The training set is used to train the model, while the validation set is used to evaluate the model’s performance.
Data Normalization
Normalize the data to ensure that all features have similar scales. This is particularly important for algorithms that are sensitive to the scale of the input variables.
By following these steps, you can ensure that your data is clean, properly formatted, and ready for training a machine learning model.
Building and Training Machine Learning Models with Amazon SageMaker
Once you have prepared your data, you can proceed to build and train machine-learning models using Amazon SageMaker. SageMaker offers a variety of options for building models, from using built-in algorithms to customizing your own models using popular frameworks like TensorFlow and PyTorch.
Option 1: Using built-in algorithms
SageMaker provides a wide range of built-in algorithms that cover various machine-learning tasks, such as classification, regression, clustering, and recommendation. These algorithms are highly optimized for scale and performance, making them suitable for large-scale machine-learning projects.
To use a built-in algorithm in SageMaker, you need to follow these steps:
- Prepare your data in the required format for the specific algorithm.
- Select the appropriate algorithm from the list of built-in algorithms in SageMaker.
- Set the hyperparameters for the algorithm. These are the parameters that control the behaviour of the algorithm, such as learning rate, number of hidden layers, or maximum tree depth.
- Train the model using the training data.
- Evaluate the model’s performance using the validation data.
SageMaker takes care of all the underlying infrastructure and automatically scales the training process to handle large datasets. This allows you to focus on the model development and analysis.
Option 2: Customizing your own models
If you prefer to customize your own models using popular frameworks like TensorFlow or PyTorch, SageMaker provides a flexible environment for doing so. You can bring your own code and libraries, and SageMaker will take care of the infrastructure and scaling.
To build and train a custom model in SageMaker, follow these steps:
- Prepare your data in the required format for your model.
- Write your model code using the chosen framework, such as TensorFlow or PyTorch.
- Set up a training job in SageMaker, specifying the location of your training data, the entry point to your training code, and the required resources.
- Start the training job and monitor the progress.
- Once the training is complete, evaluate the model using the validation data.
SageMaker provides a range of instance types and sizes to suit your specific needs. You can choose the appropriate instance type based on factors such as the size of your dataset, the complexity of your model, and the desired training time.
Evaluating and Fine-tuning Your Machine Learning Models
After training a machine learning model, it is important to evaluate its performance and fine-tune it for better results. This section will explore the techniques and tools available in Amazon SageMaker for evaluating and improving the performance of your models.
Evaluating Model Performance
Evaluating the performance of a machine learning model is crucial to ensure that it is making accurate predictions on unseen data. There are several metrics commonly used for this purpose, depending on the type of problem and the nature of the data.
For classification problems, common evaluation metrics include accuracy, precision, recall, and F1 score. Accuracy measures the overall correctness of the model’s predictions, while precision and recall provide insights into the model’s ability to correctly identify positive instances and avoid false positives or false negatives. The F1 score is a harmonic mean of precision and recall, providing a balanced measure of the model’s performance.
For regression problems, evaluation metrics include mean squared error (MSE), root mean squared error (RMSE), and mean absolute error (MAE). MSE and RMSE measure the average squared difference between the predicted and actual values, while MAE measures the average absolute difference.
In Amazon SageMaker, you can use the built-in evaluation metrics provided by the algorithms, or you can define your own custom evaluation metrics if needed. SageMaker also provides tools for visualizing the evaluation results, making it easier to understand and interpret the performance of your models.
Fine-tuning Models with Hyperparameter Optimization
Hyperparameters are parameters that are not learned from the data but need to be set before training the model. Examples of hyperparameters include learning rate, regularization strength, and batch size. The choice of hyperparameters can significantly impact the performance of a machine-learning model.
In Amazon SageMaker, you can use the Automatic Model Tuning feature to automatically search for the best set of hyperparameters for your model. This feature employs techniques like Bayesian optimization or grid search to explore the hyperparameter space and find the optimal values.
To use Automatic Model Tuning in SageMaker, follow these steps:
- Define the hyperparameters to tune and their search ranges.
- Specify the objective metric to optimize. This could be accuracy, F1 score, or any other relevant metric.
- Set the maximum number of training jobs and the maximum number of concurrent training jobs.
- Start the hyperparameter tuning job and monitor the progress.
- Once the tuning is complete, select the best model based on the objective metric.
By fine-tuning your models with Automatic Model Tuning, you can improve their performance and achieve better results.
Deploying and Managing Machine Learning Models with Amazon SageMaker
Once you have trained and fine-tuned your machine-learning models, it’s time to deploy them and make predictions on new, unseen data. Amazon SageMaker provides a seamless and integrated environment for deploying and managing machine learning models at scale.
Deploying Models for Real-time Predictions
SageMaker allows you to deploy trained models as endpoints, which can be accessed via API calls for making real-time predictions. This is useful for applications that require low-latency predictions, such as fraud detection or real-time recommendations.
To deploy a model for real-time predictions in SageMaker, follow these steps:
- Create an endpoint configuration, specifying the type and number of instances to use.
- Create an endpoint using the endpoint configuration.
- Test the endpoint by making API calls with new input data.
- Monitor the endpoint’s performance and scale it up or down as needed.
SageMaker automatically handles the scaling and load balancing of the endpoints, ensuring that your models can handle high-volume predictions efficiently.
Deploying Models for Batch Predictions
In addition to real-time predictions, SageMaker supports batch predictions, which allow you to make predictions on large datasets in an offline fashion. This is useful for scenarios where low latency is not a requirement, such as batch processing or generating reports.
To deploy a model for batch predictions in SageMaker, follow these steps:
- Create a batch transform job, specifying the location of the input data and the output location for the predictions.
- Set the batch size and the number of instances to use for processing the data.
- Start the batch transform job and monitor the progress.
- Once the job is complete, retrieve the predictions from the output location.
Batch transform jobs in SageMaker are highly scalable and can handle large datasets efficiently. You can also use the built-in parallelization feature to speed up the processing time.
Real-world Examples and Success Stories of Using Amazon SageMaker
To truly understand the power of Amazon SageMaker, let’s explore some real-world examples and success stories of organizations that have leveraged this platform to achieve significant results.
1. Netflix
Netflix, the world’s leading streaming service, uses SageMaker to personalize recommendations for its millions of subscribers. By analyzing user behaviour and preferences, Netflix is able to deliver highly targeted recommendations, resulting in increased user engagement and satisfaction.
2. Airbnb
Airbnb, the popular online marketplace for vacation rentals, uses SageMaker to optimize pricing for hosts. By analyzing various factors such as location, demand, and amenities, Airbnb is able to provide hosts with optimal pricing recommendations, leading to increased bookings and revenue.
3. GE Healthcare
GE Healthcare, a global leader in medical technology, uses SageMaker to develop machine-learning models for medical imaging analysis. By leveraging SageMaker’s powerful capabilities, GE Healthcare is able to improve the accuracy and efficiency of medical diagnoses, ultimately leading to better patient outcomes.
These are just a few examples of how organizations are using Amazon SageMaker to unlock the power of machine learning and drive meaningful outcomes. With its comprehensive set of tools and services, SageMaker empowers organizations to leverage the full potential of their data and make informed decisions.
Conclusion
When it comes to deploying and managing machine learning models, Amazon SageMaker offers a comprehensive set of tools and services that make the process seamless and efficient. With SageMaker, you can build, train, and deploy models at scale, without having to worry about the underlying infrastructure.
One of the key advantages of SageMaker is its ability to handle the entire machine-learning workflow. From data preprocessing to model evaluation, SageMaker provides a range of features that simplify the process. For instance, you can use SageMaker’s built-in algorithms for common machine learning tasks, or bring your own custom algorithms using popular frameworks like TensorFlow or PyTorch.
In summary, Amazon SageMaker provides a powerful platform for deploying and managing machine learning models. Its comprehensive set of tools and services simplifies the entire workflow, allowing you to focus on building and deploying models that drive impactful outcomes for your organization.


