Amazon Neptune: The Ultimate Guide to AWS's Graph Database Service

AWS partner dedicated to startups
- 2000+ Clients
- 5+ Years of Experience
- $10M+ saved on AWS
Amazon Neptune stands out as a pivotal service within AWS’s extensive portfolio, offering a fully managed graph database engineered to manage highly connected datasets efficiently. This guide delves into the core aspects of Amazon Neptune, highlighting its features, use cases, and the value it brings to modern applications requiring intricate data relationships.
Table of Contents
Understanding Amazon Neptune
What is Amazon Neptune?
Amazon Neptune is a fast, reliable, and fully managed graph database service provided by Amazon Web Services (AWS). It is specifically designed for storing and querying highly connected data, making it an ideal choice for applications that rely on complex datasets such as social networks, recommendation engines, and fraud detection systems. Neptune supports popular graph models like Property Graph and W3C’s RDF, along with their respective query languages, Apache TinkerPop Gremlin and SPARQL.
What is a Graph Database?
A graph, in the context of database systems, is a structure consisting of nodes (also known as vertices) and edges (links or relationships). Each node represents an entity, such as a person, place, thing, or concept, while edges depict the relationships or interactions between these entities. This flexible and intuitive model mirrors the interconnected nature of data in real-world applications, from social networks where users are connected by friendships to business ecosystems where transactions link customers, products, and vendors. Graphs excel in scenarios where relationships are as critical as the data points themselves, enabling queries that explore the depth and breadth of connections to uncover patterns, insights, and opportunities hidden within the data. By prioritizing relationships, graph databases like Amazon Neptune facilitate a deeper analysis of data relationships, making them indispensable tools for applications that rely on the intricate interplay between diverse data elements.
How Amazon Neptune Works
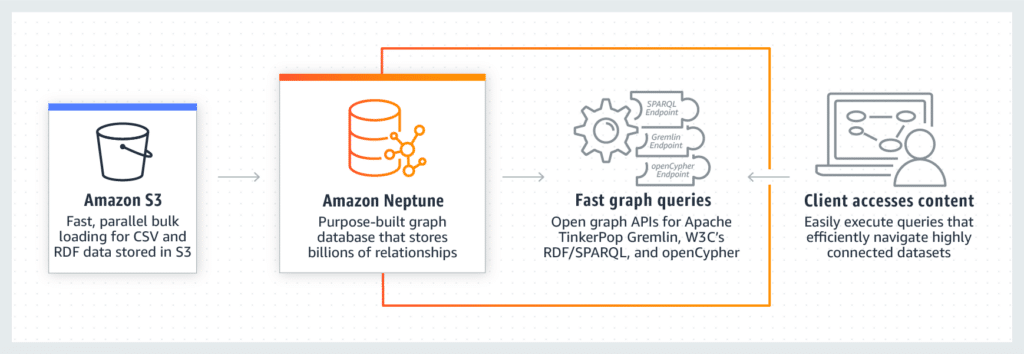
Amazon Neptune is designed to offer a robust, scalable solution for managing graph data. At its core, Neptune stores and processes data in formats that are optimized for high connectivity and complex relationship traversals, enabling rapid query responses and data retrieval. The service employs a distributed, fault-tolerant architecture that ensures data availability and resilience, automatically replicating data across multiple Availability Zones in an AWS Region. This architecture not only facilitates high availability but also enables Neptune to provide consistent performance at scale, regardless of the size of the dataset or the complexity of the queries. By leveraging fast, parallel bulk loading from Amazon S3, Neptune allows for efficient data ingestion, making it easier to get started with large datasets. Additionally, Neptune’s query processing engine is designed to optimize query execution, automatically translating high-level graph queries into efficient, low-level operations. This sophisticated processing capability, combined with Neptune’s support for both Gremlin and SPARQL query languages, empowers developers to build flexible, powerful applications that can navigate complex data relationships with ease.
Key Features and Benefits of Amazon Neptune
High Performance and Scalability
Neptune is engineered from the ground up for high performance and is capable of handling over 100,000 graph queries per second. It supports automatic scaling, allowing for up to 15 read replicas across three Availability Zones to extend read capacity and maintain low-latency access to data.
Fully Managed Service
As a fully managed service, Neptune abstracts away the complexities of hardware provisioning, software patching, and setup, enabling developers to focus on building their applications. AWS takes care of the operational burden, offering a seamless experience for managing graph databases.
Security and Compliance
Hosted within Amazon Virtual Private Cloud (VPC), Neptune ensures data isolation and secure connections. It integrates with AWS Identity and Access Management (IAM) for access control and supports encryption at rest and in transit, meeting the stringent security and compliance requirements of various industries.
Seamless Integration with AWS Ecosystem
Neptune is designed to work seamlessly with the broader AWS ecosystem, including services like Amazon S3 for data storage, AWS Lambda for executing code in response to triggers, and Amazon Kinesis for real-time data streaming. This integration enables developers to build comprehensive, cloud-native applications that leverage the strengths of AWS services.
Serverless and Global Database Capabilities
Neptune offers a serverless option, eliminating the need to manage database capacity and allowing you to pay only for the resources your application consumes. Additionally, the Neptune Global Database feature enables the deployment of a single graph database across multiple AWS Regions, reducing latency and improving disaster recovery capabilities.
Machine Learning Integration
With Neptune ML, developers can enhance their applications with machine learning capabilities. Powered by Amazon SageMaker, Neptune ML automates the heavy lifting involved in selecting, training, and optimizing machine learning models, making it easier to generate predictions directly from graph data.
Multi-Model Support
Neptune supports multiple graph models, including Property Graph and RDF (Resource Description Framework), along with their respective query languages, Apache TinkerPop Gremlin and SPARQL. This multi-model support allows developers to choose the most appropriate data model for their specific application needs, whether they’re working with highly connected data sets or leveraging semantic web data.
Continuous Backup and Point-in-Time Recovery
Neptune provides continuous backup to Amazon S3, enabling point-in-time recovery for your databases. This feature ensures data durability and recoverability, allowing you to restore your database to any second within the backup retention period, which can be crucial for maintaining data integrity in the event of accidental deletions or database corruption.
These key features make Amazon Neptune a powerful and versatile choice for developers and organizations looking to harness the power of graph databases to manage complex and highly connected data sets efficiently.
Use Cases for Amazon Neptune
Amazon Neptune’s versatility shines across various domains, demonstrating its capability to handle complex, highly connected datasets with ease. Here’s an expanded look at its use cases, incorporating insights from the additional resources.
Building Identity Graphs
Identity graphs play a crucial role in understanding customer behavior across multiple platforms and devices. Amazon Neptune facilitates the creation of comprehensive identity graphs by linking customer identifiers such as devices, email addresses, and social media profiles. This unified view enables personalized marketing strategies and targeted advertising, enhancing customer engagement and conversion rates. By leveraging Neptune, organizations can achieve a 360° view of their customers, understanding their journey and preferences in unprecedented detail. This capability is particularly beneficial for advertising technology companies, marketing agencies, and businesses aiming to enhance customer data platforms with a focus on privacy regulation compliance.
Enhancing Fraud Detection Mechanisms
Fraud detection is a critical concern for businesses worldwide, with organizations losing billions annually to fraudulent activities. Neptune’s graph database structure is ideally suited for uncovering complex fraud schemes, including those perpetrated by sophisticated fraud rings. By visualizing the relationships between transactions, accounts, and other entities, Neptune enables real-time detection of fraudulent patterns. This approach is not only more efficient but also more effective than traditional methods, allowing for the proactive prevention of fraud across various sectors, including banking, insurance, and e-commerce.
Leveraging Machine Learning for Graph Data
Neptune ML revolutionizes the way predictions are made using graph data. By employing graph neural networks (GNNs), Neptune ML significantly enhances the accuracy of predictions, surpassing traditional machine learning methods that struggle with the complex relationships inherent in graph data. This capability is crucial for applications ranging from recommendation systems to fraud detection, where understanding the nuanced connections between data points can lead to more informed and accurate outcomes. Neptune ML democratizes access to advanced machine learning techniques, enabling developers to deploy sophisticated models without deep expertise in data science.
Securing IT Infrastructure with Security Graphs
Security graphs represent a novel approach to managing and enhancing the security of IT infrastructure. By mapping out the relationships between assets, users, and access permissions, Neptune helps organizations identify vulnerabilities and potential attack vectors within their systems. This comprehensive view is invaluable for proactive threat detection, incident response, and compliance with security policies. Security graphs are particularly effective in layered security environments, where understanding the interplay between different security measures can reveal gaps and redundancies. With Neptune, organizations can model their security posture as a graph, enabling more effective defense strategies against both internal and external threats.
Getting Started with Amazon Neptune
Creating and Managing a Neptune Database
Setting up a Neptune database involves a few straightforward steps, starting with the AWS Management Console. Users can configure their database instances, including security settings and network access, and begin loading data to start building their graph applications.
Querying Data with Gremlin and SPARQL
Neptune supports two powerful query languages: Gremlin for Property Graphs and SPARQL for RDF models. These languages enable developers to efficiently query and manipulate highly connected data, uncovering insights that would be challenging to obtain with traditional databases.
Integrating Neptune with AWS Services
Neptune’s value is further amplified when integrated with other AWS services, such as Amazon S3 for data storage, AWS Lambda for serverless computing, and Amazon SageMaker for machine learning. These integrations allow for building sophisticated, scalable applications that leverage the full power of AWS’s cloud ecosystem.
Best Practices for Using Amazon Neptune
Adhering to best practices is crucial to maximize the benefits of Amazon Neptune in managing highly connected datasets. These guidelines not only ensure optimal performance but also enhance the security, scalability, and maintainability of your graph database applications.
Optimize Data Modeling
Data modeling is a critical step in the effective use of Neptune. Design your graph model to reflect the queries you anticipate running. This involves structuring nodes, edges, and properties in a way that aligns with your application’s access patterns. For Property Graphs, use labels and property keys efficiently to facilitate fast retrieval. For RDF graphs, leverage named graphs and efficient IRI (Internationalized Resource Identifiers) strategies to categorize and access your data effectively.
Utilize Indexing Strategically
While Neptune automatically manages indexing, understanding how your queries interact with these indexes can lead to performance improvements. For Gremlin, ensure that your queries are using property-based filtering early in the traversal to take advantage of Neptune’s indexing. In SPARQL queries, use FILTER clauses judiciously and consider graph-specific optimizations for faster query execution.
Manage Connections Wisely
Connection management is pivotal in ensuring the high availability and responsiveness of your Neptune database. Implement connection pooling to reduce the overhead of establishing connections to Neptune. This is particularly important for applications with high request rates. Additionally, monitor your connection usage and adjust your pool size based on the workload to avoid throttling.
Scale Effectively
Leverage Neptune’s scalability features to accommodate your application’s growth. Use read replicas to distribute query load and enhance read throughput, especially for read-intensive applications. Monitor your database’s performance metrics through Amazon CloudWatch to identify when scaling is needed, whether it’s adding more replicas or resizing your instances.
Ensure Data Security
Data security in Neptune involves multiple layers, including network security, access control, and data encryption. Use Amazon VPC to isolate your database and control access with security groups. Implement fine-grained access control with IAM policies and database authentication. Enable encryption at rest and in transit to protect your data from unauthorized access.
Backup and Recovery
Regularly back up your Neptune database to safeguard against data loss. Neptune’s continuous backup feature allows for point-in-time recovery, enabling you to restore your database to any second within the backup retention period. Test your backup and recovery procedures to ensure they meet your business continuity requirements.
Monitor and Audit
Continuous monitoring and auditing are essential for maintaining the health and security of your Neptune database. Use Amazon CloudWatch to track operational metrics and set alarms for anomalous activity. Enable logging and use AWS CloudTrail for auditing access and changes to your Neptune environment, helping you comply with regulatory requirements and internal policies.
Leverage Neptune Features and AWS Ecosystem
Take full advantage of Neptune’s features, such as the Gremlin and SPARQL query languages, to efficiently interact with your graph data. Integrate Neptune with other AWS services like Amazon SageMaker for machine learning, AWS Lambda for serverless computing, and Amazon Elasticsearch Service for advanced search capabilities to build comprehensive, cloud-native applications.
By following these best practices, you can optimize your use of Amazon Neptune, ensuring that your graph database applications are secure, scalable, and performant. This will enable you to derive maximum value from your highly connected datasets, driving insights and innovation in your organization.
Conclusion
Amazon Neptune represents a significant advancement in managing highly connected data, offering unparalleled performance, scalability, and ease of use. Whether for driving recommendation engines, enhancing fraud detection, or building comprehensive knowledge graphs, Neptune provides a robust, secure, and fully managed graph database solution. As businesses continue to navigate the complexities of modern data landscapes, Neptune stands ready to support their most challenging graph database needs.
Additional Resources
- Amazon Neptune Pricing (Understand the cost structure of Amazon Neptune and how pricing works for different configurations and usage patterns.)
- Amazon Neptune FAQs (Find answers to frequently asked questions about Amazon Neptune, covering a wide range of topics from features to management.)
- AWS Learning Path: Getting Started with Amazon Neptune (A learning resource for beginners to get started with Amazon Neptune, including tutorials and best practices.)
- Bulk Load Data to Neptune – Gremlin Format (Learn how to prepare and bulk load data into Neptune using the Gremlin format for graph data.)
- Accessing Neptune Graphs using Gremlin (A guide on how to access and query your graph data in Neptune using the Gremlin query language.)
- Bulk Load Data to Neptune – openCypher Format (Instructions on how to bulk load data into Neptune using the openCypher format, suitable for property graph models.)
- Accessing Neptune Graphs using openCypher (Explore how to use the openCypher query language to access and interact with your graph data in Neptune.)
- Bulk Load Data to Neptune – RDF Format (Discover how to bulk load RDF formatted data into Neptune, enabling efficient data ingestion for RDF graph models.)
- Accessing Neptune Graphs using SPARQL (A comprehensive guide to querying RDF graph data in Neptune using the SPARQL query language.)
These resources provide valuable information and practical guidance for anyone looking to leverage Amazon Neptune for graph database solutions, from beginners to advanced users.


